
Type “why does AI ignore my brand” into Google, and you get over 1.90 billion results. It has become the default question that teams ask the moment ChatGPT recommends a competitor instead of them. And honestly, this reaction makes sense.
The top AI Overview response makes the issue sound simple: missing context, weak mentions, inconsistent signals.
However, that’s not entirely true; generative models assemble answers from patterns they’ve learned:
- Which brands repeatedly appear near a topic
- Which domains validate them
- How clearly their information is structured
- How strongly they connect to the concepts being queried
That’s where the idea of an LLM Mention Graph becomes useful. This is the foundation of Generative Engine Optimization, strengthening the pathways that models rely on.
It’s not a ranking system. It’s a network of relationships: brands, topics, sources, citations, and co-occurrences that shape the names that feel natural for the model to include in an answer.
This blog breaks down how that network forms, why some brands get pulled in instantly, and why others stay invisible even when they’re doing “all the right things.”
What Is an LLM Mention Graph?
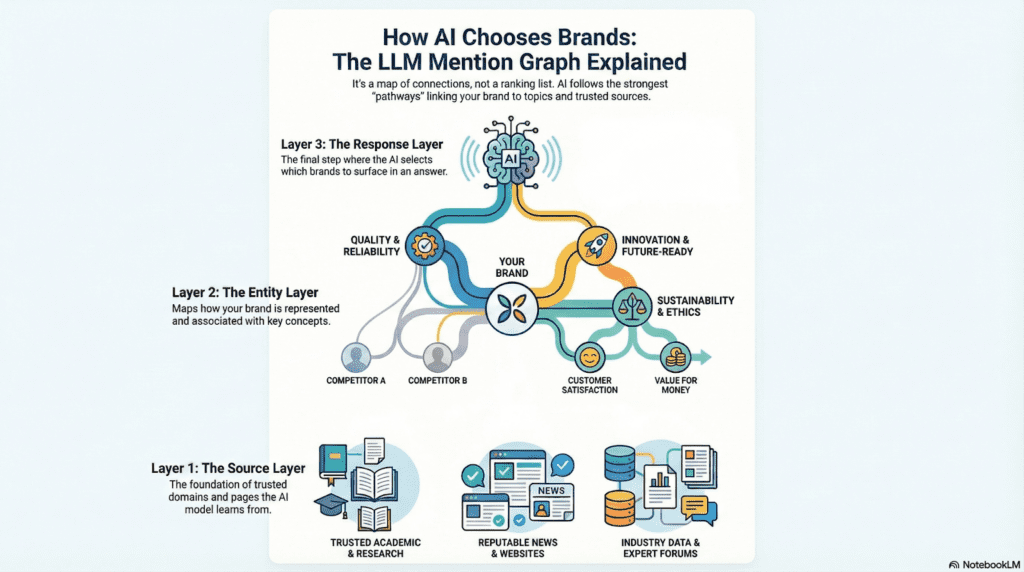
LLM Mention Graph is a map of how your brand connects to the ideas people search for.
- If your brand consistently shows up near the right keywords, on the right domains, and in the right informational contexts, the model develops a stronger “pathway” that links you to that topic.
- When those pathways grow dense, your name feels like a natural fit inside an answer.
- When they’re thin or missing, the model reaches for other brands that have clearer, more established connections.
The graph has three layers that operate together:
- Source Layer: The domains and pages the model has learned to trust for your category.
- Entity Layer: How your brand is represented, structured, and associated with key concepts.
- Response Layer: The final moment where the model selects which brands to surface inside the answer.
The model isn’t evaluating your homepage or your latest blog post in isolation. It’s following the pathways in this graph, pulling from patterns that already exist, reinforcing the ones it trusts, and avoiding the ones that lack clarity.
The Forces That Decide Whether a Brand Appears in AI Answers
Now, we know that LLMs don’t mention brands randomly. They follow a set of patterns that show up consistently across their training data, their retrieval systems, and the sources they treat as trustworthy.
Below are the core forces that influence whether a brand feels “relevant enough” for the model to include in an answer.
Citation Networks
- LLMs lean heavily on domains that appear authoritative in your category.
- If certain websites repeatedly reference the same set of brands, those brands gain stronger visibility pathways in the model.
- These citations act as anchors in the graph, shaping which names the model considers credible for specific topics.
Co-Occurrence Patterns
Models pay close attention to which brands show up together across the web. If a competitor is consistently mentioned alongside the category terms you want to own, the model builds an association between them.
This doesn’t require long-form content; short mentions, comparison tables, and listicles often create the strongest co-occurrence patterns.
High-Authority Source Presence
Some domains carry outsized influence:
- Industry publications
- Research sites
- Directories
- Government
- Educational sources
- Long-standing knowledge repositories
When your brand appears in these environments, the model strengthens its understanding of where you belong and what you should be referenced for.
Associative Clustering
- Models form clusters of brands that serve similar purposes or solve similar problems.
- These clusters become shortcuts that the model uses to build quick answers.
- Once a cluster forms: best EOR tools, leading project management platforms, top AI compliance systems, it becomes easier for the model to pull from that set when assembling recommendations.
Q/A Retrieval Patterns
- Over time, LLMs absorb the structure of common questions and the answers typically associated with them.
- If many users ask variations of the same question and the same brands appear in responses across the web, the model treats those names as part of the “default answer pattern.”
- These patterns can shift quickly when new sources, updated data, or emerging brands reshape the information landscape.
Together, these forces determine how visible your brand becomes inside AI-generated answers. They explain why some brands feel permanently anchored in a category and why others appear only occasionally, even with strong content or SEO fundamentals.
How Brands Get Pushed Out of AI Answers
Below are the primary failure patterns that routinely remove brands from AI-generated answers across ChatGPT, Perplexity, and Gemini.
Missing from High-Trust Sources
- The mention graph is weighted. A single reference from a trusted domain can outweigh dozens of mentions on low-authority blogs.
- When your brand doesn’t appear in the sources the model already uses to interpret your category: industry media, research sites, authoritative directories, the graph loses stability.
- The model has no strong signal that your brand belongs in the answer.
- What this looks like in practice: Competitors appear repeatedly in third-party explainers, while your mentions live mostly on your own domain.
Inconsistent Co-Occurrence Mapping
- If the model rarely sees your brand alongside the category terms, buyer problems, or comparison clusters that define your space, it can’t confidently link your brand to the topic the user is asking about.
- Even one competitor with a dense co-occurrence footprint will get selected over you because their pathways feel clearer.
- Example: A competitor appears in dozens of “top 10 tools” listicles or comparison tables. You appear in none.
Category Mismatch in The Content
- The model pays attention to context. If your content doesn’t use the terminology, frameworks, and descriptors that define the category conversation, you lose semantic proximity.
- This isn’t about keyword stuffing; it’s about being interpretable as part of the category. When your content doesn’t align with the informational patterns the model expects, the graph weakens.
Signal Dilution Through Technical Issues
Even strong content becomes unreliable if the underlying signals are unclear.
- Canonical conflicts
- Duplicate templates,
- Thin pages,
- Redirect chains, and
- Inconsistent metadata
All of them weaken the entity layer of the mention graph. LLM crawlers attempting to build brand clarity get inconsistent or fragmented signals, which pushes your brand out of short-listing decisions.
Crawlability Gaps (for LLM Bots)
AI crawlers behave differently from search crawlers, but the principle is identical: they can only interpret what they can access.
- Pages blocked by rules
- Buried behind weak internal linking
- Slowed down by performance issues, often never enter the model’s retrieval memory.
If your best category-defining pages are hard to fetch or parse, the model builds relationships using other brands’ pages instead.
Outdated or Infrequently Updated Content
Models value recency in topics that evolve fast: AI, security, compliance, marketing, and finance. If the web shows fresher, better-structured information for the same topic, the model gradually shifts toward those brands.
Even one outdated definition can weaken your contextual relevance and cause your brand to slip out of answer patterns.
For instance, your competitor updates their category guide every quarter; your last refresh was in 2022.
The One-Page Checklist
Six reasons your brand disappears from generative answers:
- You’re missing from the sources the model already trusts.
- You don’t co-occur consistently with core category terms.
- Your content doesn’t align with the dominant language of the space.
- Your signals are diluted by structural or canonical inconsistencies.
- LLM crawlers can’t reliably reach and parse your key pages.
- Your information is outdated relative to competitors shaping the category.
How to Improve Your LLM Mention Graph
Improving your mention graph is the core of Generative Engine Optimization, because it shapes how often models select your brand.”
| Step | What You Do | Why It Matters |
| 1. Audit Current Mentions | Check how often your brand appears in ChatGPT, Perplexity, and Gemini for priority queries. | Establishes a baseline and shows which competitors dominate. |
| 2. Identify Citation Leaders | Map the domains the model already trusts for your category. | These sources influence the source graph layer directly. |
| 3. Build Co-Occurrence Clusters | Create comparisons, ecosystem guides, and landscape explainers. | Links your brand tightly with category terms and competitor sets. |
| 4. Fix Technical Visibility Gaps | Improve crawlability, metadata consistency, URL stability, and internal linking. | Removes noise that weakens entity interpretation. |
| 5. Strengthen External Authority | Earned media, expert commentary, PR, third-party inclusions. | High-authority references shift which brands feel “cite-worthy.” |
| 6. Improve Entity Clarity | Add structured data, unified naming, and product definitions. | Reduces ambiguity around what your brand does. |
| 7. Monitor Monthly Shifts | Re-evaluate mentions, citations, and trusted sources every 30–45 days. | The mention graph is dynamic and changes quickly. |
In generative search, you’re not competing for position.
You’re competing for presence.
ReSO is an AI Search Visibility tool that reveals how often your brand is selected in model-generated answers. It maps which competitors appear for your priority queries, identifies the sources shaping those answers, surfaces the gaps in your citation and co-occurrence footprint, and highlights the technical issues that weaken your entity signals. Book a call with us to build a stronger graph, and your brand becomes part of the default answer set.







